

In Silico Prediction of Physicochemical Properties of Environmental Chemicals Using Molecular Fingerprints and Machine Learning
Zang Q, Mansouri K, Williams AJ, Judson RS, Allen DG, Casey WM, Kleinstreuer NC.
Journal of Chemical Information and Modeling (2017)
DOI: https://doi.org/10.1021/acs.jcim.6b00625
PMID: 28006899
Publication
Abstract
There are little available toxicity data on the vast majority of chemicals in commerce. High-throughput screening (HTS) studies, such as those being carried out by the U.S. Environmental Protection Agency (EPA) ToxCast program in partnership with the federal Tox21 research program, can generate biological data to inform models for predicting potential toxicity. However, physicochemical properties are also needed to model environmental fate and transport, as well as exposure potential. The purpose of the present study was to generate an open-source quantitative structure-property relationship (QSPR) workflow to predict a variety of physicochemical properties that would have cross-platform compatibility to integrate into existing cheminformatics workflows. In this effort, decades-old experimental property data sets available within the EPA EPI Suite were reanalyzed using modern cheminformatics workflows to develop updated QSPR models capable of supplying computationally efficient, open, and transparent HTS property predictions in support of environmental modeling efforts. Models were built using updated EPI Suite data sets for the prediction of six physicochemical properties: octanol-water partition coefficient (logP), water solubility (logS), boiling point (BP), melting point (MP), vapor pressure (logVP), and bioconcentration factor (logBCF). The coefficient of determination (R2) between the estimated values and experimental data for the six predicted properties ranged from 0.826 (MP) to 0.965 (BP), with model performance for five of the six properties exceeding those from the original EPI Suite models. The newly derived models can be employed for rapid estimation of physicochemical properties within an open-source HTS workflow to inform fate and toxicity prediction models of environmental chemicals.
Figures
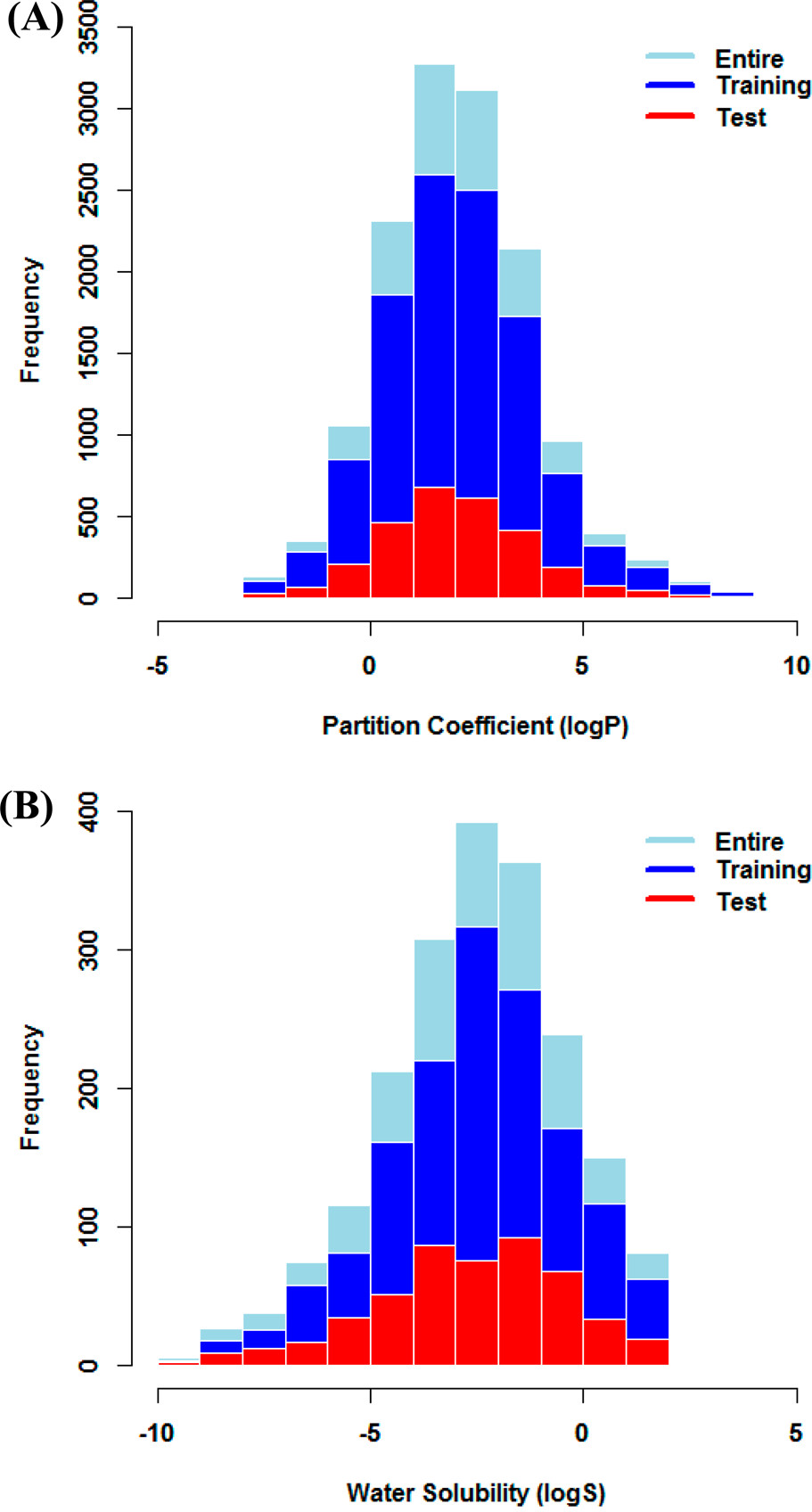
Figure 1. Data distribution of logP (A) and logS (B).
{kind=link}
{kind=link}
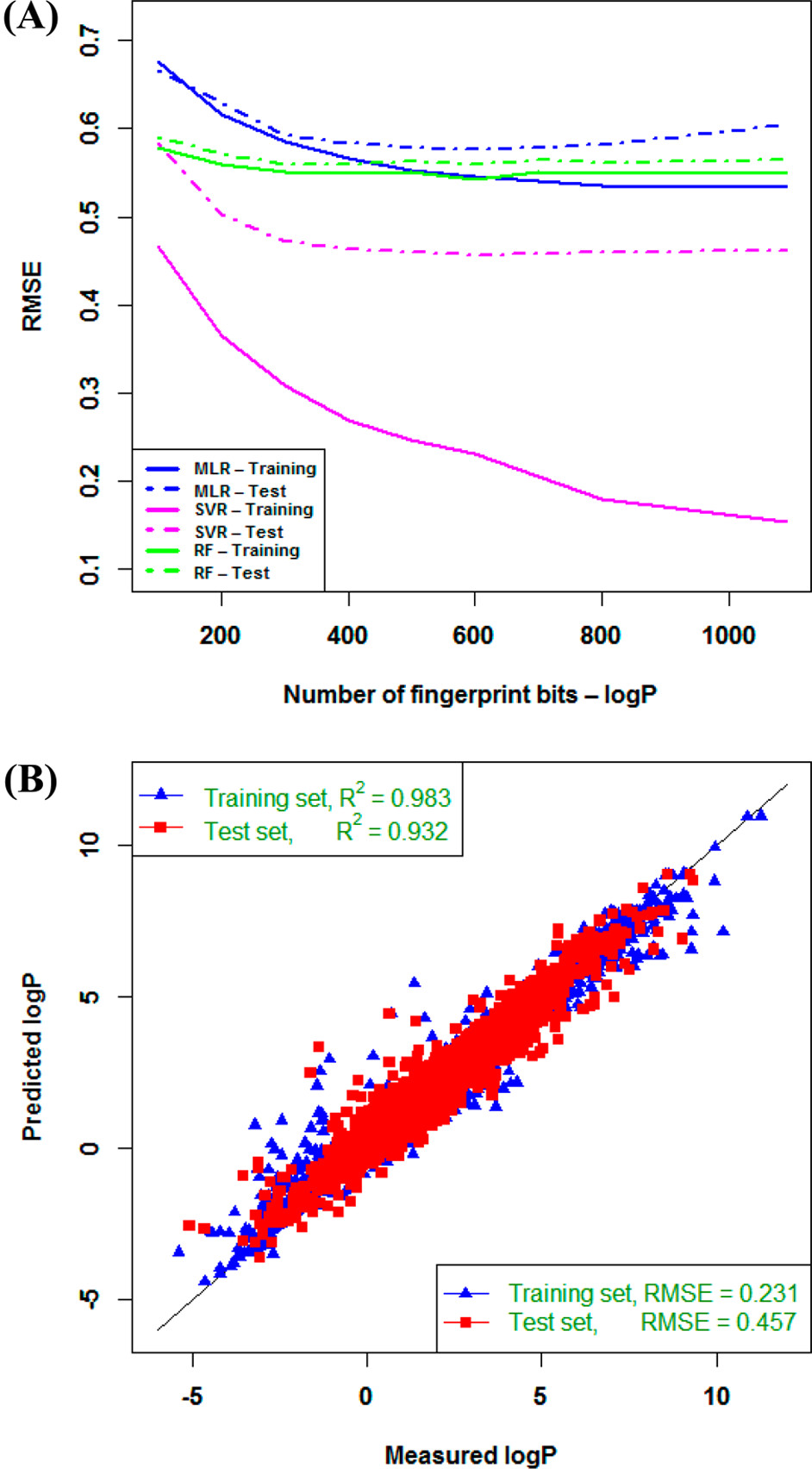
Figure 2. Relationship between model complexity and prediction errors (RMSE).
Relationship between model complexity and prediction errors (RMSE) (A) and plot of experimental data versus estimated values by SVR using 600 fingerprint bits (B) for logP.
- Figure 2 (267 KB)
{kind=link}
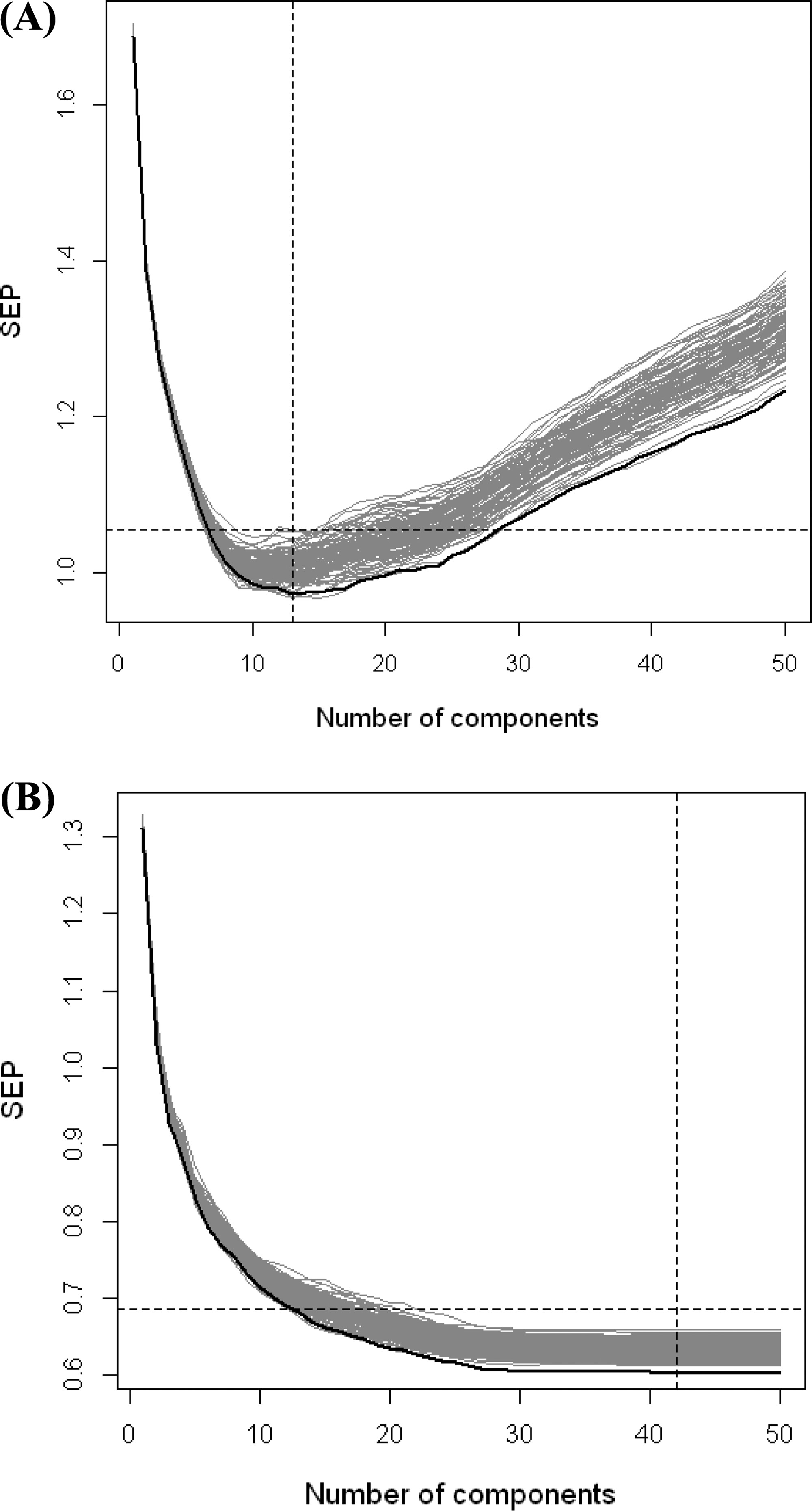
Figure 3. Relationship between the number of PCs and SEP.
Relationship between the number of principal components (PCs) and the standard error of prediction (SEP) for the PLSR model of logP. The black lines were produced from a single 10-fold CV while the gray lines correspond to 100 repetitions of the 10-fold CV. (A) Plot of SEP versus PCs for the all-bit model. (B) Plot of SEP versus PCs for the 600-bit model selected by GA.
- Figure 3 (348 KB)
{kind=link}
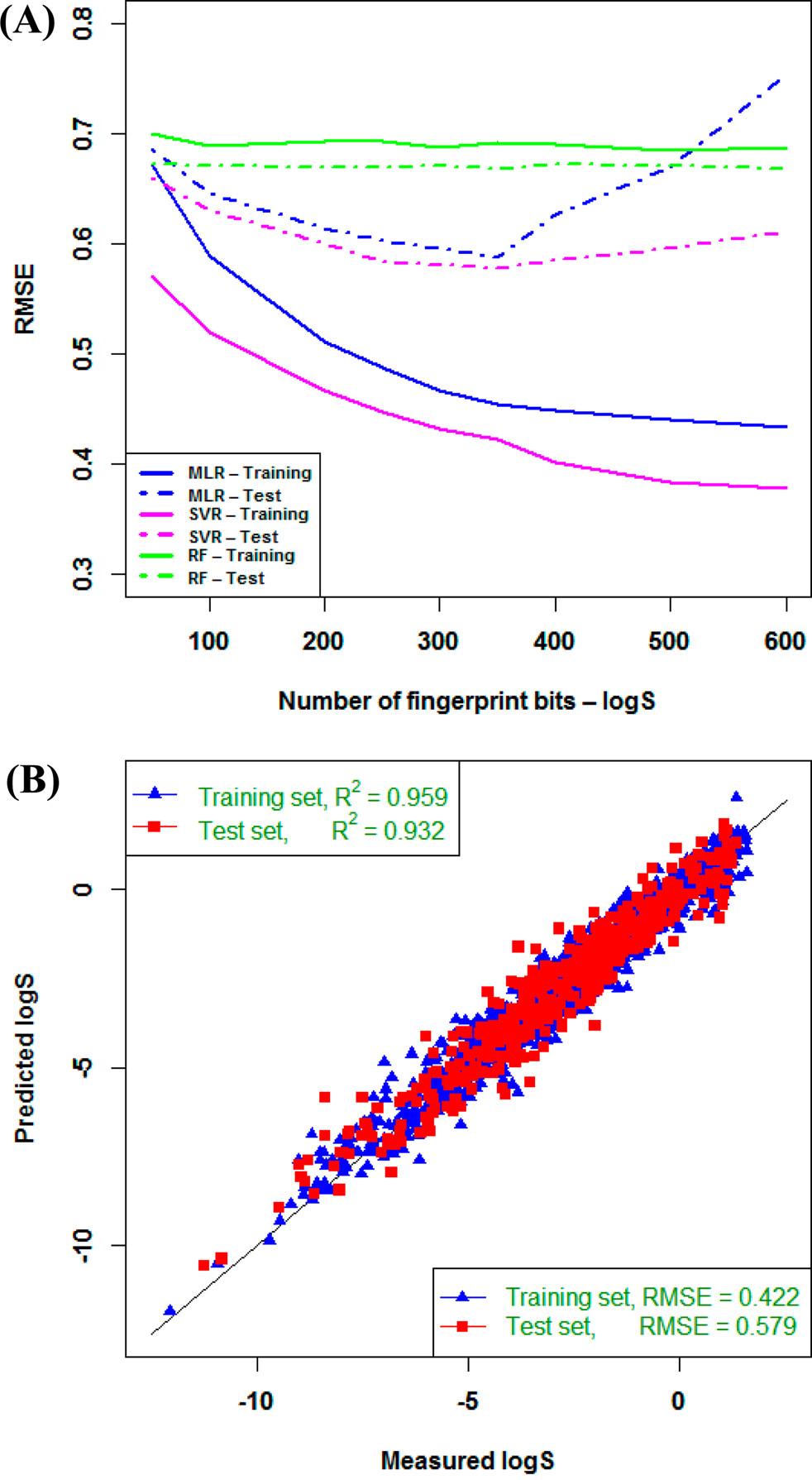
Figure 4. Relationship between model complexity and prediction errors (RMSE).
Relationship between model complexity and prediction errors (RMSE) (A) and plot of experimental data versus estimated values by SVR using 350 fingerprint bits (B) for logS.
- Figure 4 (297 KB)
{kind=link}
Figure 5. Plots of leverage versus standardized residuals for logP.
Plots of leverage versus standardized residuals for logP (A) and logS (B) models’ training and test sets. The models were built by SVR using 350 and 600 fingerprint bits for logS and logP, respectively. Vertical dashed line marks AD threshold based on the leverage value. Horizon dashed lines define a region where predictions were within two standardized residuals.
- Figure 5 (319 KB)
{kind=link}
Tables
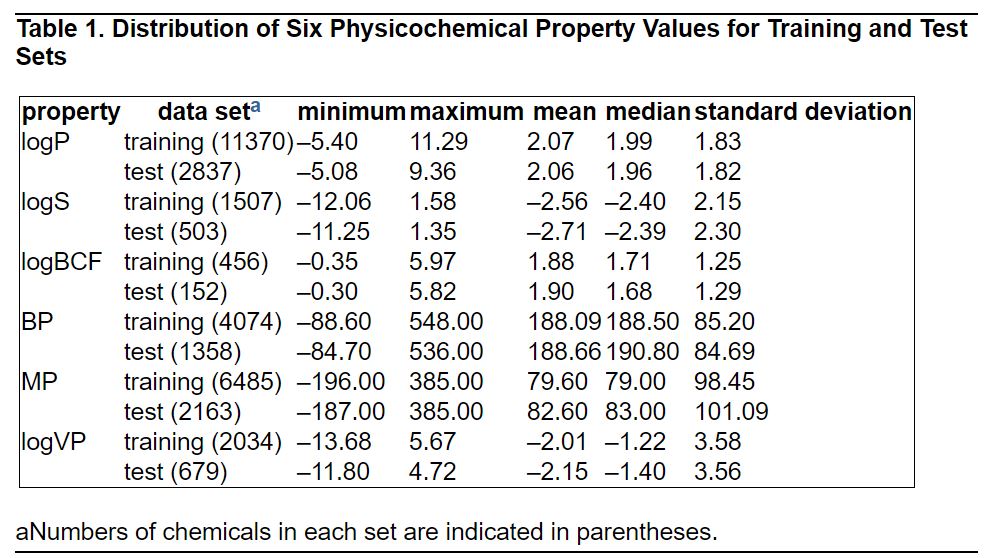
Table 1. Distribution of Six Physicochemical Property Values for Training and Test Sets.
a Numbers of chemicals in each set are indicated in parentheses.
- Table 1 (128 KB)
{kind=link}
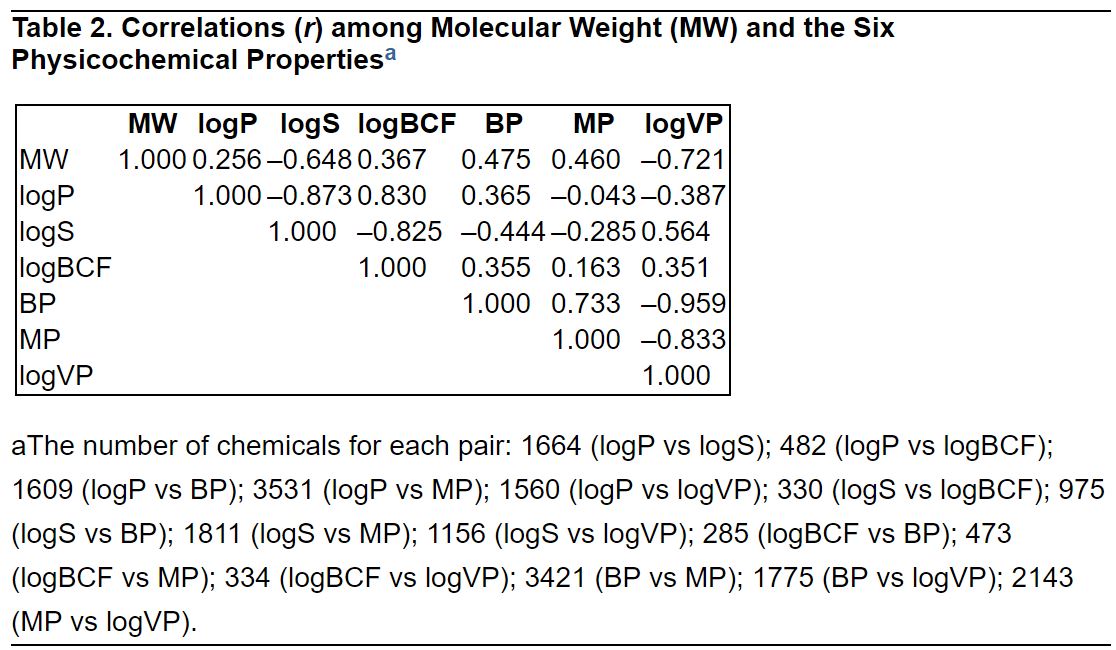
Table 2. Correlations (r) among Molecular Weight (MW) and the Six Physicochemical Properties.
a The number of chemicals for each pair: 1664 (logP vs logS); 482 (logP vs logBCF); 1609 (logP vs BP); 3531 (logP vs MP); 1560 (logP vs logVP); 330 (logS vs logBCF); 975 (logS vs BP); 1811 (logS vs MP); 1156 (logS vs logVP); 285 (logBCF vs BP); 473 (logBCF vs MP); 334 (logBCF vs logVP); 3421 (BP vs MP); 1775 (BP vs logVP); 2143 (MP vs logVP).
- Table 2 (140 KB)
{kind=link}
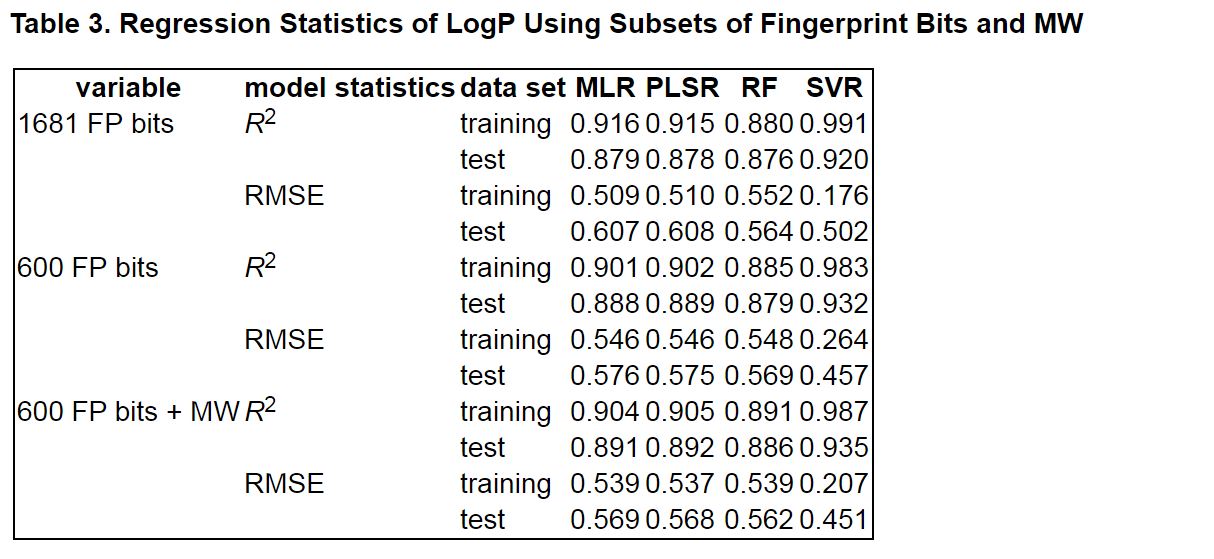
Table 3. Regression Statistics of LogP Using Subsets of Fingerprint Bits and MW.
- Table 3 (119 KB)
{kind=link}
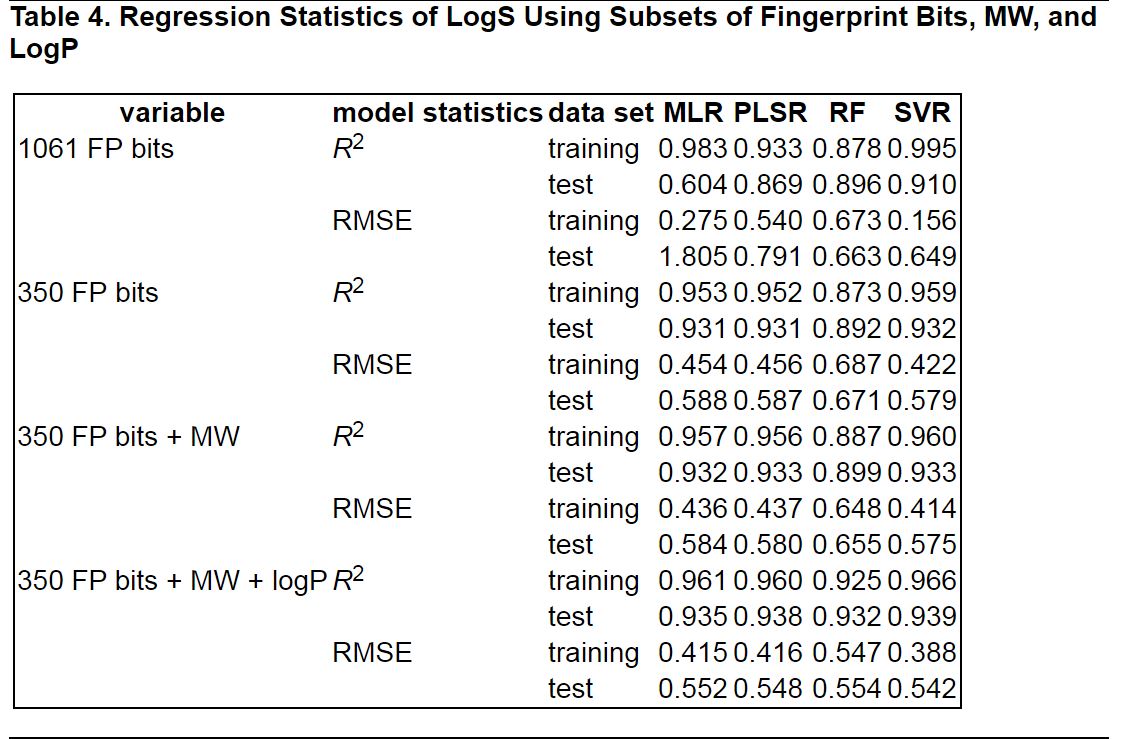
Table 4. Regression Statistics of LogS Using Subsets of Fingerprint Bits, MW, and LogP.
- Table 4 (153 KB)
{kind=link}
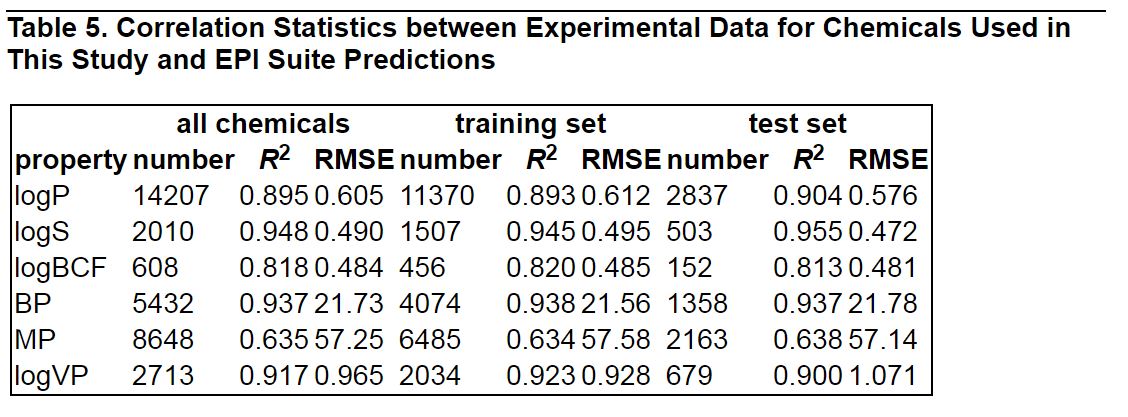
Table 5. Correlation Statistics between Experimental Data.
Correlation Statistics between Experimental Data for Chemicals Used in This Study and EPI Suite Predictions.
- Table 5 (115 KB)
{kind=link}
Table 6. Applicability Domain (AD) of LogP and LogS Models: Test Set Evaluation.
aThe models were built by SVR using 600 FP bits + MW for logP and 350 FP bits + MW + logP for logS.
- Table 6 (139 KB)
{kind=link}
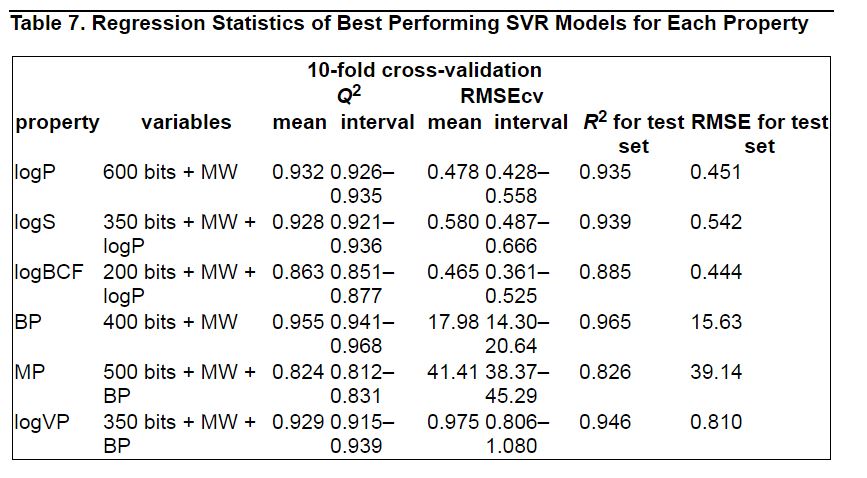
Table 7. Regression Statistics of Best Performing SVR Models for Each Property.
- Table 7 (91 KB)
{kind=link}
Supplemental Materials
Supplemental Data
QSAR Model Reporting Formats. Examples of R code: feature selection and regression analysis. Figure S1: Data distribution of logBCF, BP, MP and logVP. Figures S2–S5: Relationship between model complexity and prediction errors as well as the plots of estimated values versus experimental data for logBCF, BP, MP, and logVP, respectively. Figure S6: Plots of leverage versus standardized residuals for logBCF, BP, MP, and logVP models. Table S1: Chemical product classes for training and test sets. Tables S2–S5: Regression statistics for logBCF, BP, MP, and logVP, respectively. Table S6: Applicability domains for logBCF, BP, MP, and logVP. Tables S7–S12: Chemicals with large prediction residuals for the six properties (PDF).
Chemical names, CAS registry number and SMILES as well as experimentally measured and estimated property values of the training and test sets (XLSX).
- Chemical Properties (3 MB)
- QSAR Model Reporting Formats (2 MB)