

Multivariate Models for Prediction of Human Skin Sensitization Hazard
Judy Strickland, Qingda Zang, Michael Paris, David M. Lehmann, David Allen, Neepa Choksi, Joanna Matheson, Abigail Jacobs, Warren Casey, Nicole Kleinstreuer.
Journal of Applied Toxicology (2017)
DOI: https://doi.org/10.1002/jat.3366
PMID: 27480324
Publication
Abstract
One of the Interagency Coordinating Committee on the Validation of Alternative Method's (ICCVAM) top priorities is the development and evaluation of non-animal approaches to identify potential skin sensitizers. The complexity of biological events necessary to produce skin sensitization suggests that no single alternative method will replace the currently accepted animal tests. ICCVAM is evaluating an integrated approach to testing and assessment based on the adverse outcome pathway for skin sensitization that uses machine learning approaches to predict human skin sensitization hazard. We combined data from three in chemico or in vitro assays - the direct peptide reactivity assay (DPRA), human cell line activation test (h-CLAT) and KeratinoSens™ assay - six physicochemical properties and an in silico read-across prediction of skin sensitization hazard into 12 variable groups. The variable groups were evaluated using two machine learning approaches, logistic regression and support vector machine, to predict human skin sensitization hazard. Models were trained on 72 substances and tested on an external set of 24 substances. The six models (three logistic regression and three support vector machine) with the highest accuracy (92%) used: (1) DPRA, h-CLAT and read-across; (2) DPRA, h-CLAT, read-across and KeratinoSens; or (3) DPRA, h-CLAT, read-across, KeratinoSens and log P. The models performed better at predicting human skin sensitization hazard than the murine local lymph node assay (accuracy 88%), any of the alternative methods alone (accuracy 63-79%) or test batteries combining data from the individual methods (accuracy 75%). These results suggest that computational methods are promising tools to identify effectively the potential human skin sensitizers without animal testing. Published 2016. This article has been contributed to by US Government employees and their work is in the public domain in the USA.
Figures
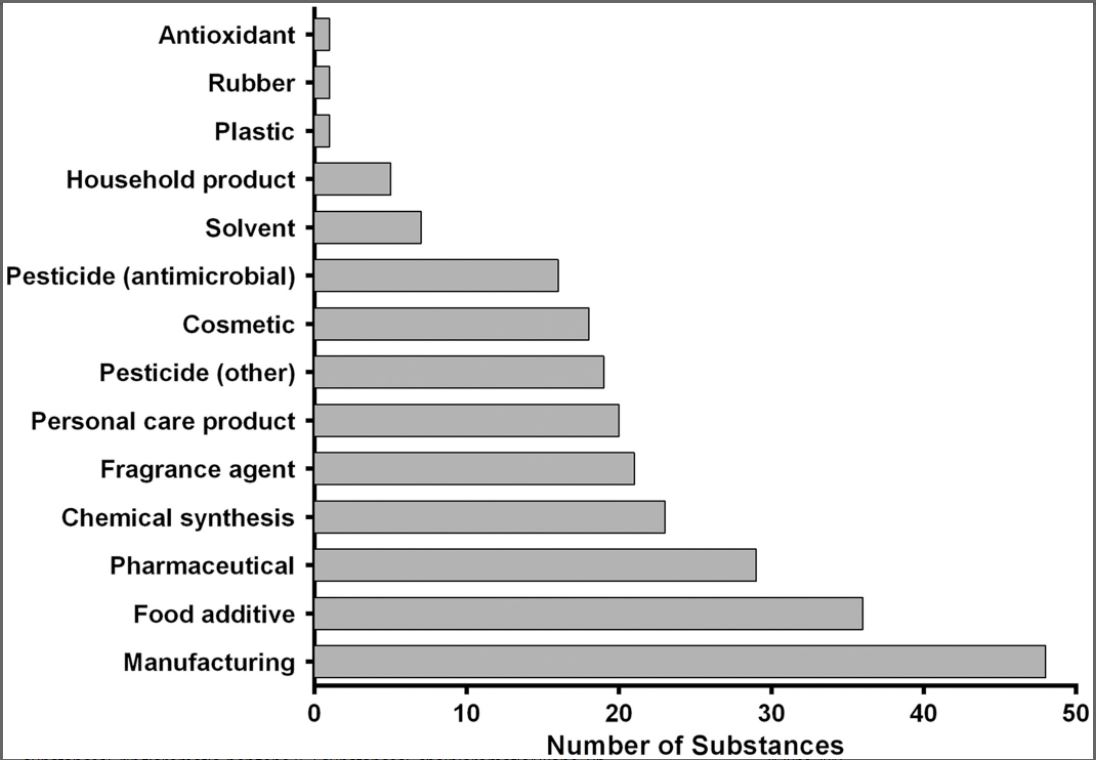
Figure 1. Product uses for 96 substances in the database.
Total number of substances exceeds 96 because most substances were associated with more than one product use.
- Figure 1 (73 KB)
{kind=link}
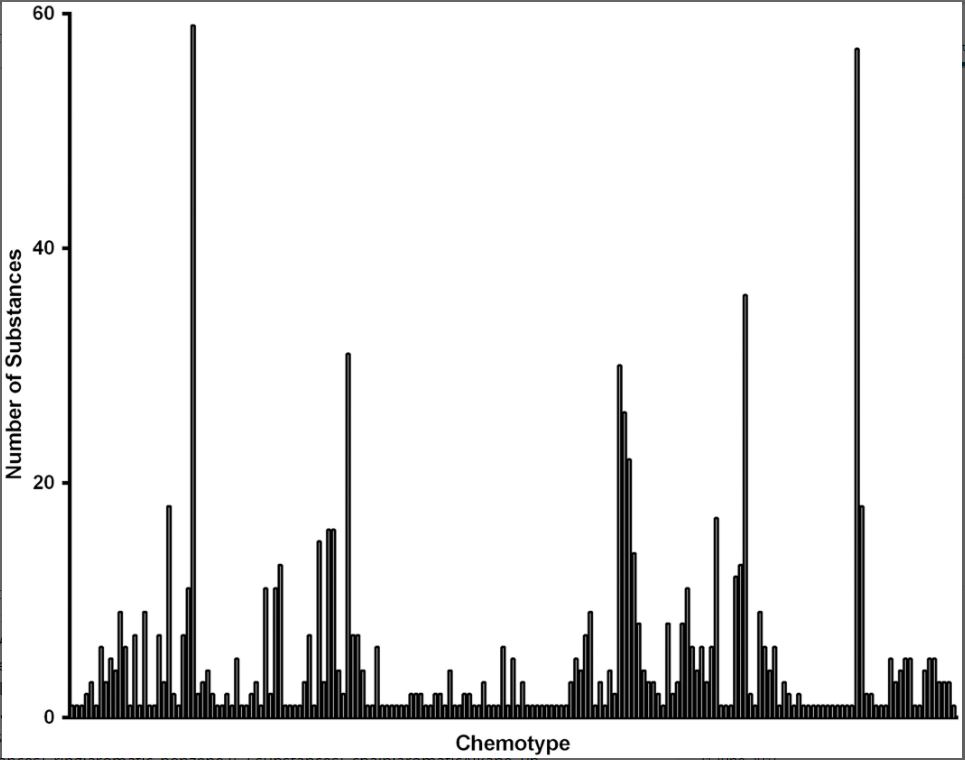
Figure 2. Frequency of appearance of 183 chemotypes for the 96 substances in the database.
Height of bars represents the number of substances that included each of the 183 chemotypes.
- Figure 2 (57 KB)
{kind=link}
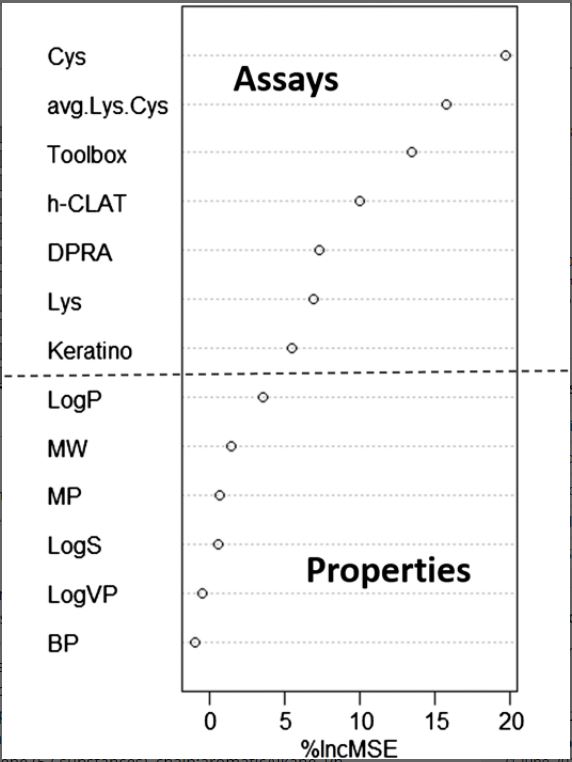
Figure 3. Ranking of variable importance by random forest algorithm.
Avg.Lys.Cys, average percentage depletion for lysine and cysteine peptides from the DPRA; BP, boiling point; Cys, average percent depletion of cysteine peptide from the DPRA; DPRA, direct peptide reactivity assay binary result; h‐CLAT, human cell line activation test; %IncMSE, percent increase in mean squared error; Keratino, KeratinoSens assay; log P, log octanol/water partition coefficient; log S, log water solubility; log VP, log vapor pressure; Lys, average percent depletion of lysine peptide from the DPRA; MP, melting point; MW, molecular weight; Toolbox, read‐across prediction from QSAR Toolbox.
- Figure 3 (48 KB)
{kind=link}
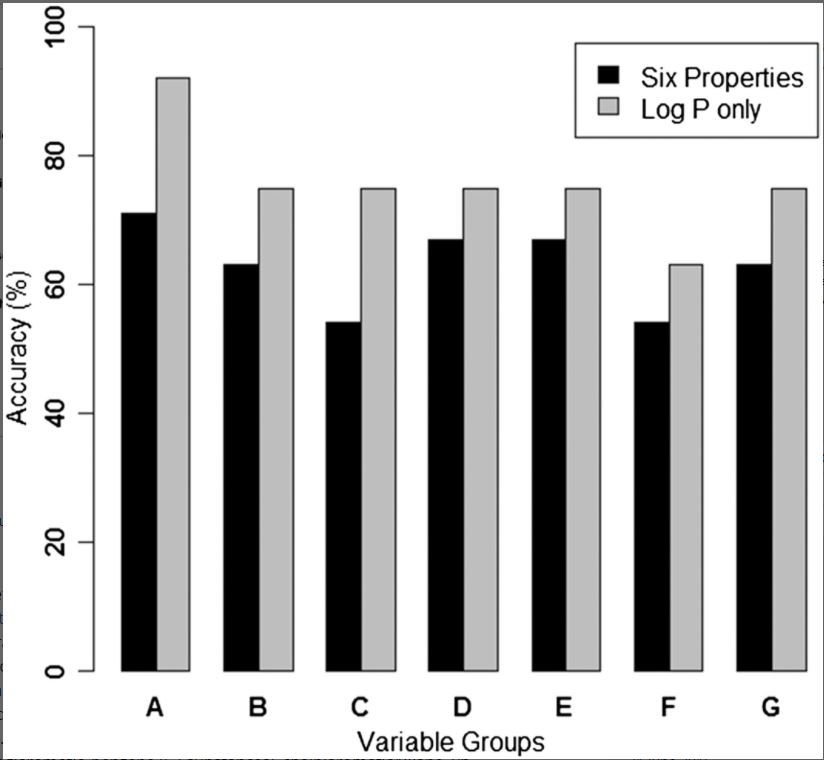
Figure 4. Logistic regression models: comparison of accuracy for test set for variable groups.
Logistic regression models: comparison of accuracy for test set for variable groups containing either six physicochemical properties or log P. Test set contained nine non‐sensitizers and 15 sensitizers. Variable groups A–G are defined in Table 4. Log P, log octanol/water partition coefficient.
- Figure 4 (58 KB)
{kind=link}
Figure 5. Support vector machine models: comparison of accuracy for test set for variable groups.
Support vector machine models: comparison of accuracy for test set for variable groups containing either six physicochemical properties or log P. Test set contained nine non‐sensitizers and 15 sensitizers. Variable groups A–G are defined in Table 4. Log P, log octanol/water partition coefficient.
- Figure 5 (58 KB)
{kind=link}
Tables
Table 1. Data sources.
- Table 1 (126 KB)
Table 2. Data types and ranges of 13 input variables.
- Table 2 (160 KB)
Table 3. Variable groups used to build models for predicting human skin sensitization hazard.
- Table 3 (130 KB)
Table 4. Performance of LR and SVM models: test and training sets.
- Table 4 (179 KB)
Table 5. Performance of leave‐one‐out cross‐validation for LR and SVM models for 96 substances.
- Table 5 (108 KB)
Table 6. Misclassified substances for the six LR and SVM models with the highest performance.
- Table 6 (175 KB)
Table 7. Performance of individual methods and the LLNA for predicting human skin sensitization.
Performance of individual methods and the LLNA for predicting human skin sensitization hazard compared with machine learning approaches
- Table 7 (144 KB)
Supplemental Materials
Supporting Information
- Read-Across Protocol (30 KB)
- Supplemental Information (422 KB)
- Test-Training Set Comparison (451 KB)