

Prediction of Skin Sensitization Potency Using Machine Learning Approaches
Zang Q, Paris M, Lehmann DM, Bell S, Kleinstreuer N, Allen D, Matheson J, Jacobs A, Casey W, Strickland J.
Journal of Applied Toxicology (2017)
DOI: https://doi.org/10.1002/jat.3424
PMID: 28074598
Publication
Abstract
The replacement of animal use in testing for regulatory classification of skin sensitizers is a priority for US federal agencies that use data from such testing. Machine learning models that classify substances as sensitizers or non-sensitizers without using animal data have been developed and evaluated. Because some regulatory agencies require that sensitizers be further classified into potency categories, we developed statistical models to predict skin sensitization potency for murine local lymph node assay (LLNA) and human outcomes. Input variables for our models included six physicochemical properties and data from three non-animal test methods: direct peptide reactivity assay; human cell line activation test; and KeratinoSens™ assay. Models were built to predict three potency categories using four machine learning approaches and were validated using external test sets and leave-one-out cross-validation. A one-tiered strategy modeled all three categories of response together while a two-tiered strategy modeled sensitizer/non-sensitizer responses and then classified the sensitizers as strong or weak sensitizers. The two-tiered model using the support vector machine with all assay and physicochemical data inputs provided the best performance, yielding accuracy of 88% for prediction of LLNA outcomes (120 substances) and 81% for prediction of human test outcomes (87 substances). The best one-tiered model predicted LLNA outcomes with 78% accuracy and human outcomes with 75% accuracy. By comparison, the LLNA predicts human potency categories with 69% accuracy (60 of 87 substances correctly categorized). These results suggest that computational models using non-animal methods may provide valuable information for assessing skin sensitization potency.
Figures
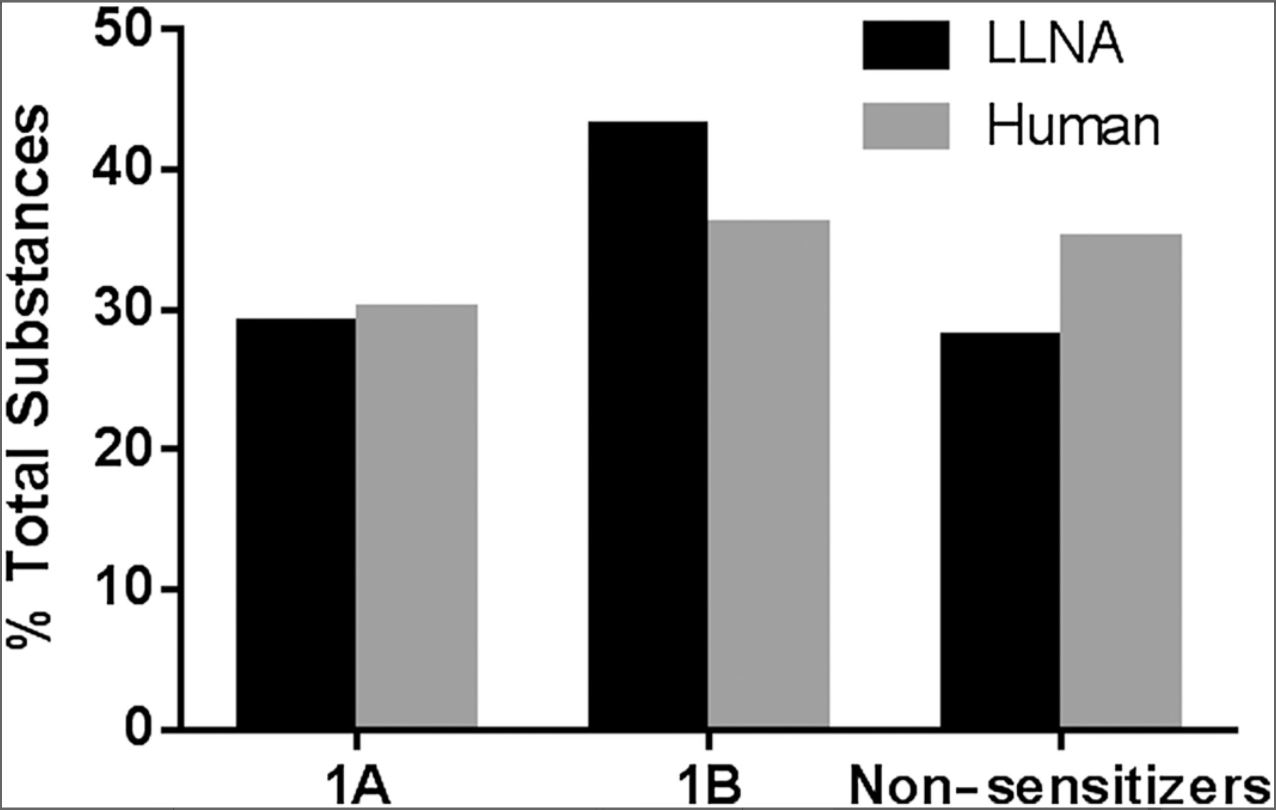
Figure 1. Distribution of substances for the LLNA and human databases.
Distribution of substances for the LLNA and human databases across the three GHS categories of skin sensitization. LLNA database contains 120 substances, including 35 1A (strong) sensitizers and 52 1B (weak) sensitizers. Human database contains 87 substances, including 26 1A sensitizers and 31 1B sensitizers. GHS, United Nations Globally Harmonized System of Classification and Labeling; LLNA, murine local lymph node assay.
- Figure 1 (65 KB)
{kind=link}
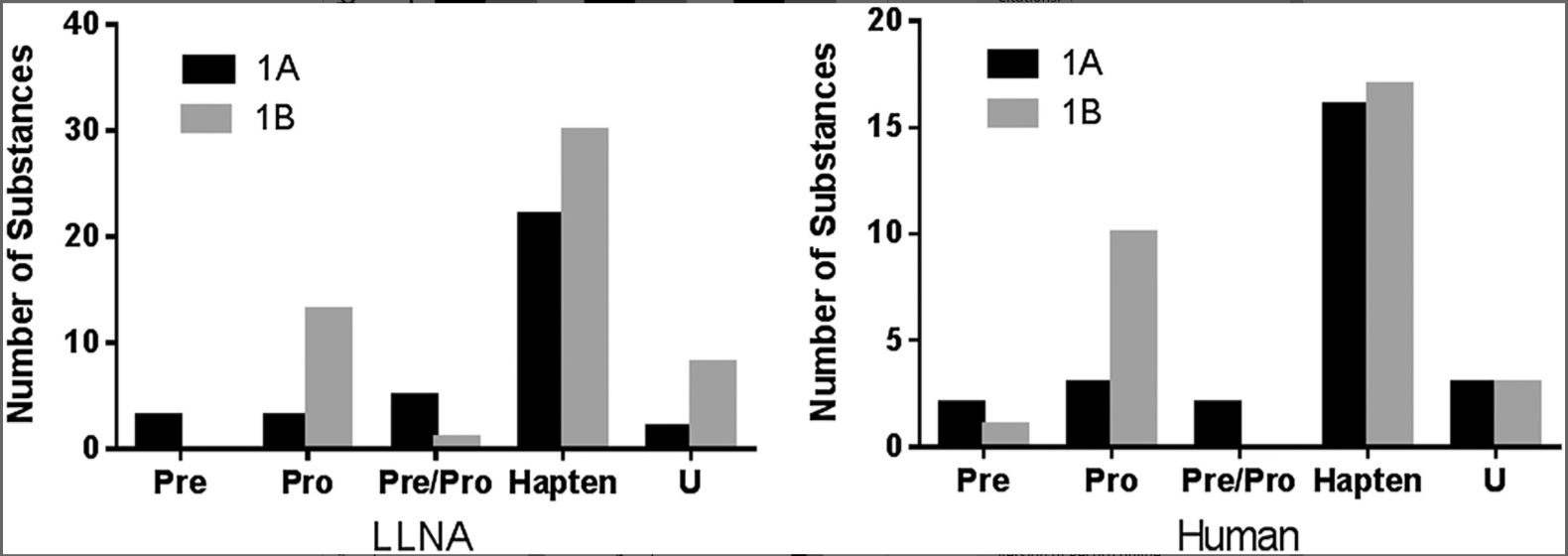
Figure 2. Distribution of prehaptens, prohaptens and pre/prohaptens.
Distribution of prehaptens, prohaptens and pre/prohaptens across the GHS 1A and 1B categories of skin sensitizers. There are 87 LLNA sensitizers (35 1A [strong] and 52 1B [weak]) and 57 human sensitizers (26 1A and 31 1B). GHS, United Nations Globally Harmonized System of Classification and Labeling; LLNA, murine local lymph node assay; Pre, prehapten; Pre/Pro, pre‐ and /or prohapten; Pro, prohapten; U, unknown.
- Figure 2 (70 KB)
{kind=link}
Figure 3. Distributions of (a) DPRA, (b) h‐CLAT and (c) KeratinoSens values for substances.
Distributions of (a) DPRA, (b) h‐CLAT and (c) KeratinoSens values for substances identified as GHS 1A and 1B sensitizers by LLNA and human data. Boxplot is graphed based on the data quartiles, which divide the distribution into the 25% (Q1), 50% (Q2) and 75% (Q3) percentiles. Height of the box is determined by Q1 and Q3 while the median or Q2 is represented by the dark line inside the box. Avg.Lys.Cys, average depletion of lysine and cysteine peptides; DPRA, direct peptide reactivity assay; EC1.5, concentration producing a 1.5‐fold induction of luciferase activity; h‐CLAT, human cell line activation test; GHS, Globally Harmonized System of Classification and Labeling of Chemicals (UN, 2015); LLNA, murine local lymph node assay. [Colour figure can be viewed at wileyonlinelibrary.com]
- Figure 3 (56 KB)
{kind=link}
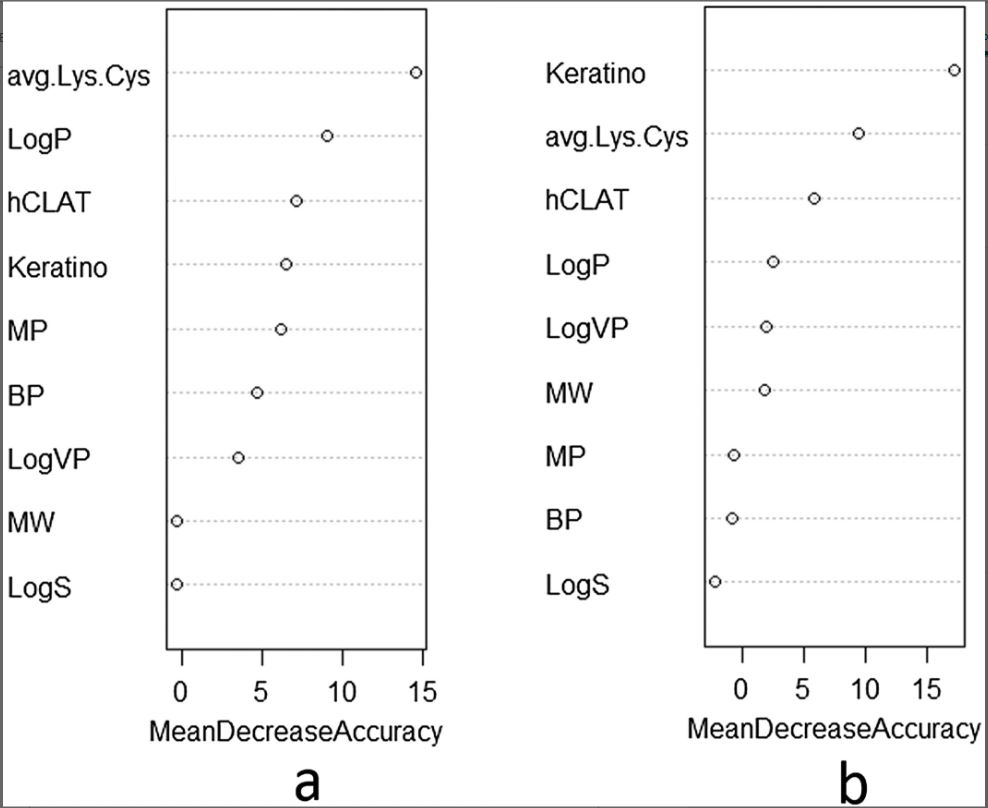
Figure 4. Ranking of variable importance by random forest algorithm.
Ranking of variable importance by random forest algorithm for (a) LLNA data set and (b) human data set for distinguishing between GHS 1A and 1B sensitizers. Avg.Lys.Cys, average depletion of lysine and cysteine peptides; BP, boiling point; GHS, Globally Harmonized System of Classification and Labeling of Chemicals (UN, 2015); hCLAT, minimum induction values of the CD86 EC150 and the CD54 EC200; Keratino, EC1.5 for the induction of luciferase activity controlled by the antioxidant response element; LLNA, murine local lymph node assay; LogP, log octanol/water partition coefficient; LogS, log water solubility; LogVP, log vapor pressure; MP, melting point; MW, molecular weight.
- Figure 4 (69 KB)
{kind=link}
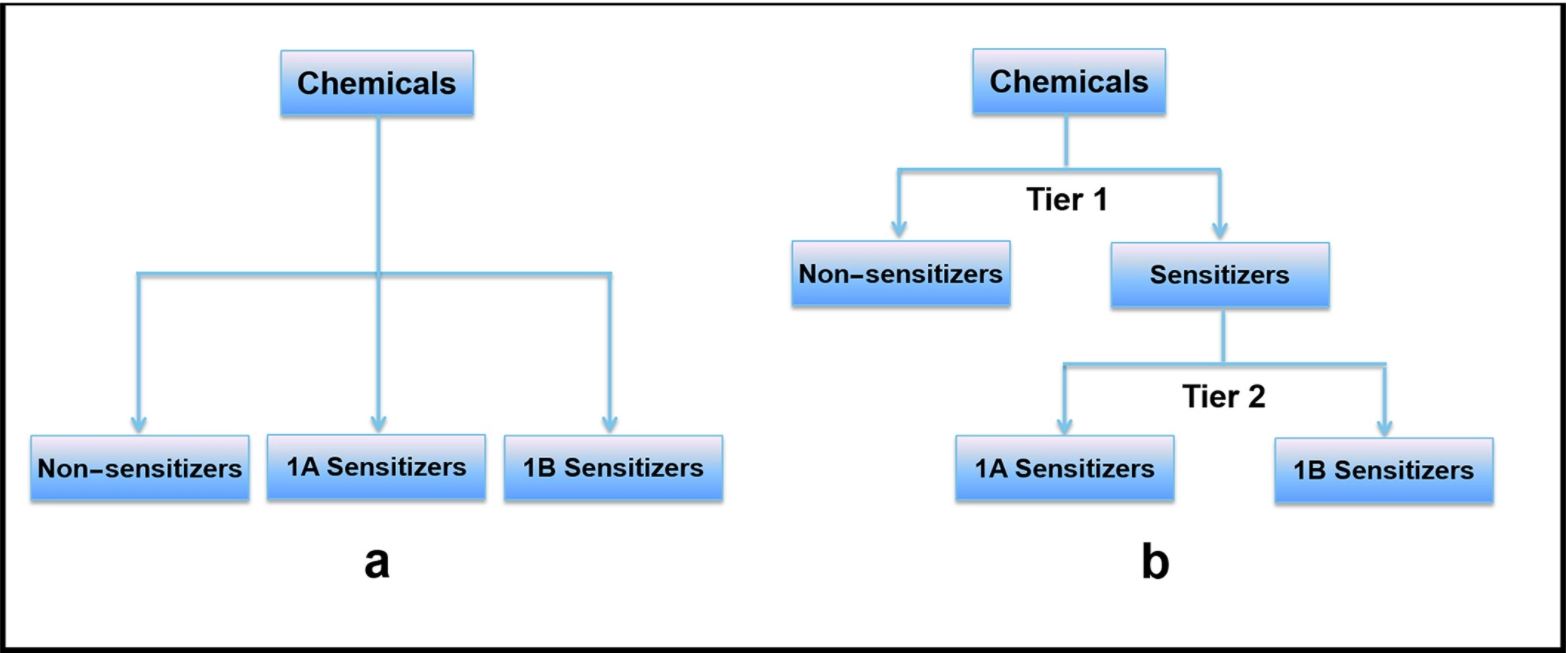
Figure 5. Two classification strategies for modeling three categories of sensitization potency.
- Figure 5 (69 KB)
{kind=link}
Tables
Table 1. GHS potency categories.
- Table 1 (119 KB)
Table 2. Data ranges of input variables.
- Table 2 (139 KB)
Table 3. Distributions of training and test substances.
- Table 3 (126 KB)
Table 4. Variable sets for model building.
- Table 4 (105 KB)
Table 5. Accuracy of individual category and overall classification predictions.
Accuracy of individual category and overall classification predictions using strategy Aa and SVM.
LLNA, murine local lymph node assay; LOOCV, leave‐one‐out cross‐validation; SVM, support vector machine.
Values after “±” indicate 95% confidence limits of proportion for correct classification rate.
a Strategy A modeled all three categories of response simultaneously.
b LLNA data set contained 120 substances: 35 strong sensitizers, 52 weak sensitizers and 33 non‐sensitizers. Human data set contained 87 substances: 26 strong sensitizers, 31 weak sensitizers and 30 non‐sensitizers.
c 1A (strong) and 1B (weak) are subcategories for sensitizers in the Globally Harmonized System of Classification and Labeling of Chemicals (UN, 2015).
- Table 5 (163 KB)
Table 6. Individual category accuracy and overall accuracy of sensitizer classification.
Individual category accuracy and overall accuracy of sensitizer classificationa from tier 2 of strategy B using four machine learning approaches.
CART, classification and regression tree; LDA, linear discriminant analysis; LR, logistic regression; LLNA, murine local lymph node assay; SVM, support vector machine.
Values after “±” indicate 95% confidence limits of proportion for correct classification rate.
a Chemicals predicted to be sensitizers using the Strickland et al. (2016a,b), models were used in tier 2. LLNA and human data sets respectively included 84 (34 1A and 50 1B) and 53 (26 1A and 27 1B) chemicals predicted to be sensitizers.
b Variable sets are defined in Table 4.
- Table 6 (121 KB)
Table 7. Performance of one‐tiered (A) and two‐tiered (B) classification strategies using SVM.
Performance of one‐tiered (A) and two‐tiered (B) classification strategies using SVMa.
LLNA, murine local lymph node assay; SVM, support vector machine.
Values after “±” indicate 95% confidence limits of proportion for correct classification rate.
a Leave‐one‐out cross‐validation results.
- Table 7 (146 KB)
Supplemental Materials
Supporting Information
- Supplemental Information: Chemical List (501 KB)
- Tables S1 (19 KB)
- Tables S2 (21 KB)
- Tables S3 (21 KB)
- Tables S4 (25 KB)